2014/05/05 Tang
1 引言
随着网络通信速度的提高以及通信费用大幅度的降低,IP电话在不久的将来会取代现有的大部分传统电信业务,成为未来通信的一种主流模式,但是与传统电话相比,由于回声的影响,IP电话在因特网上进行语音的实时传输话音质量较差,入耳对大于50ms的回声就能鉴别出来,而IP电话总的延迟在100 ms以上,因此如何消除IP电话中的回声已成为非常重要的问题。目前回声消除使用得最广泛的自适应算法是LMS自适应滤波算法,LMS算法是建立在维纳滤波器的基础上发展而来的,由于维纳滤波器参数是固定的,只有在对信号和噪声的统计特性先验已知的情况下才能获得最佳滤波性能,但是在实际运用中常常无法得到这些统计的先验知识,在这种情况下自适应滤波能提供优越性能,它利用前一时刻已获得的滤波参数等结果,自动地调节现时刻的滤波器参数,以适应信号和噪声随机的统计特性。常见的回声消除算法有:递归最小二乘算法(RtS)、最小均方误差算法(LMS)、能量归一化LMS算法(NLMS)、块处理算法(BLMS)等。衡量一个自适应滤波器算法性能优劣的主要参数包括收敛速度和运算量,从收敛速度来看,RLS算法明显优于LMS算法,但RLS算法在运算上比LMS算法复杂;NLMS和BLMS算法针对LMS算法步长提出了改进,提高了收敛速度,但步长的改进是以增加算法的复杂度为代价的。本文将算法的复杂度和收敛性能相结合,提出了一种改进算法,首先采用量化误差算法,使LMS算法中乘法运算转化为符号运算,大大降低了计算量;其次,采用变步长算法,使其收敛速度尽可能快。
2 改进自适应滤波算法原理
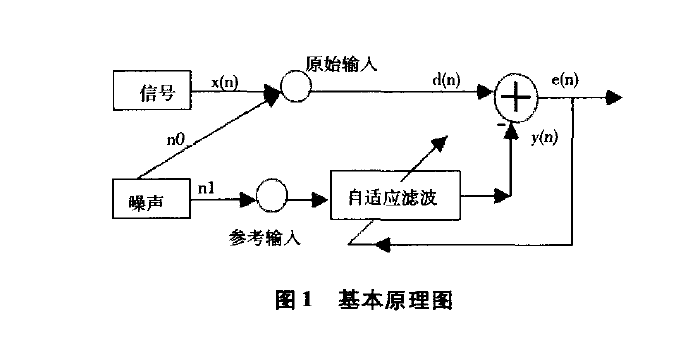
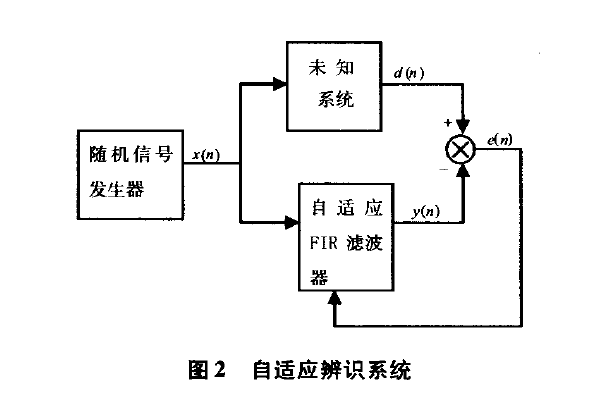
改进算法通过对算法复杂度和收敛速度的综合考虑,将量化误差算法和变步长算法相结合。变步长算法能较好的减小误差的幅度,提高收敛速度,所存在的缺点是计算复杂度大;而量化误差算法则用误差的符号来代替误差本身,减小了计算量,但会增大梯度的估计误差。因此在解决收敛速度和算法复杂度矛盾的情况下,可以考虑结合两种算法的优点,提出一种新的改进算法。改进算法的基本原理图如图1所示,x(n)表示随机信号的输入,n0,n1表示相关的噪声信号,d(n)表示期望输出信号,y(n)表示算法的实际输出信号,它由自适应滤波器来调节,它利用前一时刻已获得的滤波参数等结果,采用改进算法的权值公式自动地调节现时刻的滤波器参数,从而获得理想的误差信号,其误差值e(n)为期望输出信号与实际输出信号之差。
2.1量化误差算法
2.1.1 采用符号误差LMS算法口
这种方法是对误差信号进行量化,将LMS算法的权值调节为:W(n+1)=W(n) + μ(n)e(n)x(n) (1) 进行变形如式(2)所示:W(n+1)=W(n) + μf(e(n))x(n) (2) 上式(2)中W(n)为第步迭代的权向量,μ(n)为第n步迭代更新步长,也称为收敛因子,为确保收敛,收敛因子μ应满足0</μ<2/λ(λ是E(x(n)·x(n))的最大特征值)。对函数,f(·)取不同形式,可以得到不同的量化误差LMS算法,一般将f定义为符号函数sign,即将误差e(n)用其符号代替,即SA(sign algorithms)算法。函数f(·)表达式如下式:
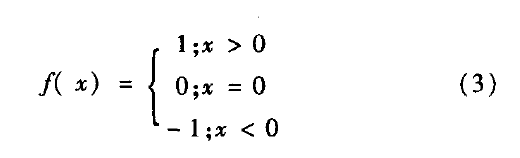
这样一来将乘法运算转化为符号函数,从而大大的降低了计算量,由原来的2N个乘法器和2N个加法器才能实现的计算量简化为,N个移位器和2N个加法器实现的计算量,算法的物理实现难度被大大降低。
2.1.2 采用符号数据LMS算法
为了减轻LMS算法计算复杂度,除了对误差e(n)进量化外,还可对输人数据x(n)进行量化也就是SRA(sign- data algorithms)算法。将LMS算法的权值调节公式进行变形如式(4)所示: W(n+1)=W(n) + μe(n)f(x(n)) (4) 对函数f(·)取不同形式,其形式与上面相同。在符号数据算法中,梯度向量
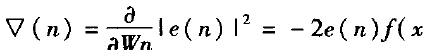
平均梯度方向只能沿着某些离散的方向进行更新,这可能引起更新过程中平方误差的频繁增加,从而导致不稳定。所以一般采用符号误差算法来减少计算量。
2.2 可变步长LMS自适应滤波算法
文献[5]分析指出,由于在信号输入端不可避免的存在干扰噪声,LMS算法将产生失调噪声,干扰噪声越大,引起的失调噪声也就越大。减少步长因子,可以减少自适应滤波算法的稳态失调噪声。然而步长因子的减小,将降低算法的收敛精度和跟踪速度。因此,固定步长的LMS算法在收敛速度,跟踪速度及失调噪声之间的要求是相互矛盾的。因此在选择步长时,需要在稳态误差和收敛速度之间折衷考虑,可变步长算法基本上遵循如下调整原则:在初始收敛阶段或未知系统参数发生变化时,步长应比较大,以便有较快的收敛速度或对时变系统的跟踪速度;而在算法收敛后,不管主输入端干扰信号有多大,都应保持很小的调整步长以达到很小的稳态失调噪声。这样才能够在信道性能比较差的情况下得到一个相对比较小的均方误差。可变步长算法的步长因子μ(n)更新公式为:
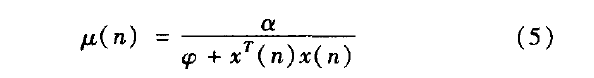
则其权值公式相应地调整为:
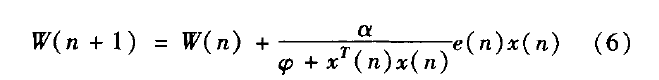
式(6)中,为控制失调的固定收敛因子,0<α<2,参数是为避免x(n)·xt(n)过小导致步长值太大而设置的。步长因子μ(n)是输入信号x(n)的非线性变量,它使步长在收敛过程中由大逐渐变小,加速了收敛过程。与固定步长的算法相比,变步长算法的优越性在于:自适应算法的开始阶段时,误差信号e(n)比较大,步长因子μ(n)也相应地变大,从而得到较快的收敛速度。当误差逐渐减小时,步长因子μ(n)相应地变小,因此稳态误差也很小,从而在收敛速度和稳态误差两方面达到了兼顾。
3 改进算法
从前面介绍的两种算法—量化误差算法和可变步长算法,可以看出变步长算法能较好的控制步长的大小,从而提高收敛速度,所存在的缺点是计算复杂度大;而量化误差算法则用误差的符号来代替误差本身,减小了计算量,因此我们可以考虑将两种算法结合起来,根据量化误差算法的计算量小以及可变步长算法的收敛速度快的优点,得到一种新的改进算法。误差信号值要达到理想的状态,其算法重点在于自适应滤波器的权值公式的调节。综合量化误差算法式(2)和可变步长算法式(6)可以得出改进算法的权值公式为:
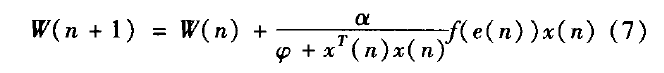
由此改进算法具体步骤可以归纳为:
1)设定滤波器权值W(n)的初始值:W(0)=0,0<μ<1;
2)计算滤波器实际输出估计值:y(n)=Wt(n)X(n);
3)计算估计误差:e(n)=d(n)-y(n);
4)定义符号函f(x)=20;0;
5)步长因子
6)计算n+1时刻的滤波器系数:W(n+1)= W(n) + μf(e(n))X(n);
7)将n增至n+1,重复步骤2)到6)。
4 改进算法的仿真分析
4.1 改进算法仿真
将改进算法一量化误差算法和变步长算法有机结合,使用Matlab工具进行仿真实验。并将改进算法的仿真结果与传统LMS算法进行比较。首先设置1000个采样点,构造一个阶次为2,截止频率为0.25Hz的巴特沃思滤波器,加入随机噪声信号进行系统辨识,如图2所示,通过随机输入信号得到辨识对象的输出,即期望输出信号d(n)。部分程序实现如下:

仿真实验中采用变步长对前60个采样点进行试验,对前20个采样点采用大步长mu=0.32,对后40个采用点采用小步长mu=0.15,修正参数fai=0.0001,按照改进算法的具体步骤,采用权值公式W=W+mu * u * f(e(n))/(r(n)+ fai)的迭代,进行循环计算,得到改进算法的实际输出信号y(n)。接着将辨识对象的输出d(n)与该改进算法得到的输出Y(n)进行相减,这样就得到了第一个误差信号e(n),这样逐步进行直到训练完成。部分程序实现如下:

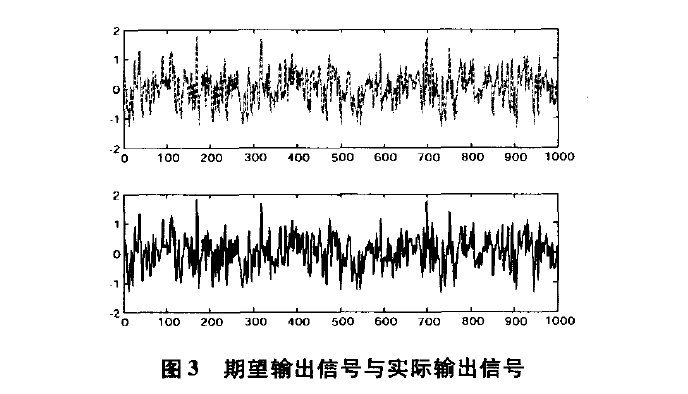
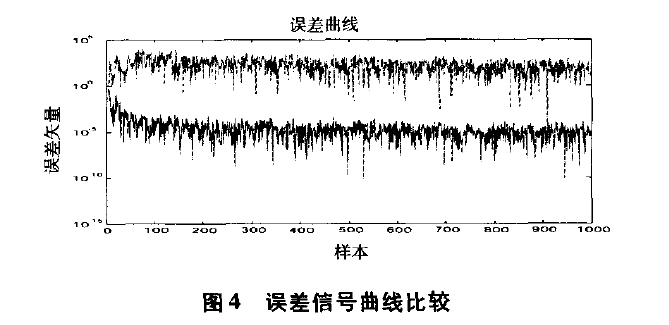
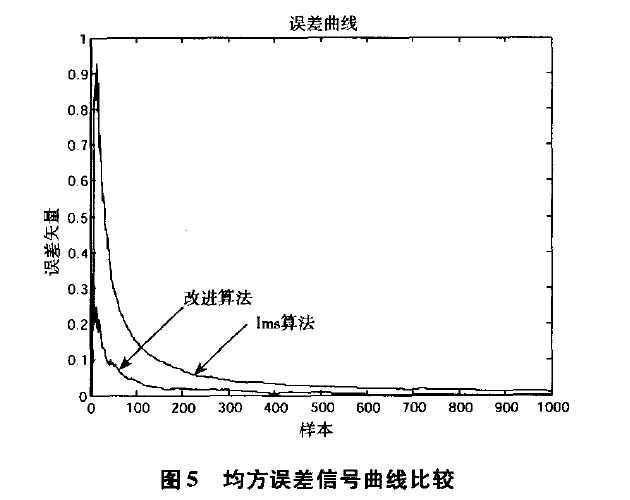
仿真结果如图3,图4和图5所示。图3分别是辨识对象的输出即期望输出信号d(n)和算法实际输出信号y(n)。图4上方曲线代表的是传统LNS算法的误差信号e(n)曲线,下方曲线代表的是改进算法的误差信号e(n)曲线,由图4可见,改进算法的误差值e(n)即实际输出y(n)与期望响应d(n)之间的差值比传统LMS算法的误差要小,误差精度也达到了满意的效果,但并不足以证明改进算法的收敛速度比传统LMS算法快。图5是改进算法和传统LMS算法的均方误差曲线比较,由图5可以知道,改进算法的误差收敛速度要比传统LMS算法快得多。从图5中可以看出,在传统 LMS算法曲线中,由于采用固定步长,前60个采样点误差收敛性能较差;而在改进算法曲线中,前60个采样点步长变化明显,由大逐渐变小,收敛速度也明显得到提高,从60点以后误差信号逐渐趋于稳定,达到理想状态,整体的误差精度也优于传统LMS算法,由此表明实验所得结果与理论分析一致。
4.2 仿真分析及评论
4.2.1改进算法仿真结果分析
1)计算量大大减小。传统LMS算法步长因子改进后,计算复杂度增加,改进算法将误差信号进行量化,其值e(n)的大小由误差的符号sign(e(n)来代替,大大降低了算法的计算量。
2)收敛速度大大加快。传统LMS算法采用固定步长,收敛速度小,改进算法将原始步长因子更新为α[φ+ x(n) · xt(n)],它是输入信号x(n)的非线性变量,随着采样次数的增加,步长由大变小,从而提高了收敛速度。由上面的两种结果的比较分析可以知道,在变步长LMS算法以及量化误差算法的基础上进行改进的这种算法,不管是在收敛速度方面还是在运算量方面,其性能都是提升的,在实际的IP电话回声消除系统运用中,也能进一步的消除噪声干扰,对设计高质量的语音通话系统是很有帮助的。
4.2.1 仿真结果评论
变步长算法在收敛程度上远胜于传统LMS算法,但其权值公式进行改进后,计算复杂度增加,而量化误差算法,将误差进行分段线性限幅函数量化,将LMS算法需要用2N个乘法器和2N个加法器才能实现的计算量简化为N个移位器和2N个加法器实现的计算量,使得计算量减小,因此针对两种算法的优缺点提出了一种改进算法,它结合了变步长算法收敛速度快和量化误差算法的计算量小的优点,从而在保证变步长算法收敛度的条件下弥补了算法的复杂度,如图3,图4和图5所示,仿真结果表明改进算法既减少了算法的计算
量,又提高了误差收敛速度。因此它能很好的运用在IP电话回声消除系统中。在实际运用中,步长因子的选择也是十分重要的,它对滤波器收敛性能有很大的影响,因为它控制了为达到最优解的算法收敛速度。本次仿真试验中采用的步长因子是经过多次测试才得到的。
5 小结
自适应信号处理的理论经过多年的发展和完善,已经在许多领域中得到应用,本文将自适应信号处理技术应用于语音通信的回声消除。传统LMS算法由于结构简单、稳定性好、易乇硬件实现等诸多优点而被广泛用于自适应控制、雷达、系统辨识及信号处理等领域。但是这种固定步长的LMS自适应算法存在着收敛速度慢的缺点。本文主要在算法复杂度和算法收敛速度这两个参数上对传统LMS算法进行改进,通过理论分析和仿真研究表明,本文提出的算法在保证精度的前提下,可大大降低算法的复杂度,并能加快算法的收敛速度,为实际运用提供了更大的灵活性,在回声系统中能较好地满足IP电话对语音的要求。从而提高了通话质量。
40088 411661033743080@qq.com
中国广东省深圳市南山区西丽九祥岭工业区10栋3楼