2014/04/17 meeteasy
1、电话会议系统的总体结构
电话会议系统的出现极大地提高了企业的工作效率,改善了企业的管理,提升了企业的竞争力。目前,市场上实现电话会议系统的方案较多,归纳起来基本属于以下两种方案:基于交换平台的交换机方案和基于语音卡的CTI(计算机通信接口)方案。
电话会议系统的总体框图如图1所示。与会用户的话音信号经过终端设备进行处理后变成8bitA律PCM话音数据传送到数据交换网,数据交换网将由用户传来的多个输入话音通道叠加到一条或几条PCM链路上进行输出,一般情况下,每32个用户可以分配一条PCM链路。叠加后的输入话音由DSP的多通道串口McBSP传输到DSP内部处理。DSP通过主机接口(HPI) 以共享信箱方式与MC68000主处理器进行通信,完成主处理 器对DSP的命令传递和实时监控。
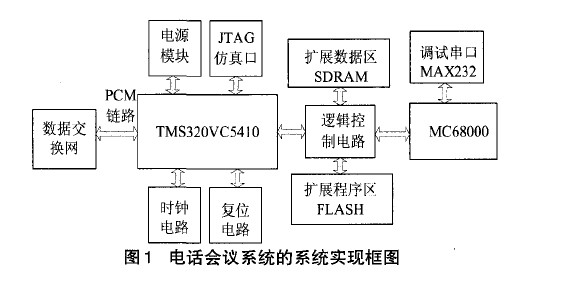
电源模块提供系统所需的两种电压:3.3V、2.5V,同时提供足够的负载电流。时钟电路提供系统所需要的时钟,DSP 芯片内部的PLL锁相环电路产生系统工作时所需的高频信号。扩展的FLASH芯片在系统中保存程序代码,同时还可以在线擦除、写入,使得系统软件编程变得十分容易。芯片的掉电保护作用,可以保证系统代码的完整性和安全性。系统的所有控制逻辑由控制逻辑模块完成
2、电话会议系统的基本原理
电话会议系统可以实现参加会议的用户之间没有障碍的交流,在现有的电话会议系统中,大多采用混音算法,但随着需要合成的语音信道数量的增加,采样量化数据叠加后会超出量化上限而引入噪声。比较算法的出现有效地避免了混音算法溢出的缺点,但是当与会人数较少或进行激烈的讨论时,同时发言的与会方不断在最大方、次大方、旁听中 切换,必将导致无论哪一方的发言都听不清楚。
针对以上所讨论的两种方法的优缺点,本文则有针对性地提出一种可以在两种模式 之间自由选择的方案。基本原理如下:以实现32方通话为例,首先在DSP中开辟一个系统信箱,用于存放DSP与主机的握手信号及主机对DSP的控制字K,K=I表示对所有与会通道进行混音处理,K≠1表示对所有与会通道进行比较处理。DSP根据主机的要求对数据进行处理,用户既可以听到所有与会人员的话音,也可以听到一路用户话音。
DSP数据接收流程如图2所示。
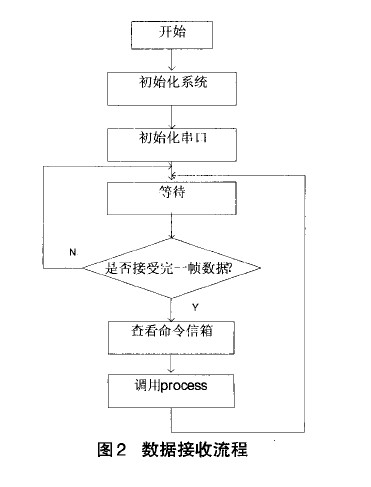
系统初始化DSP及其串口后,ST—BUS链路通过数据接口电路将数据送给McBSP,McBSP的接收端口收到8bit A律PCM话音数据后,将其转换为13bit线性码。 TMS320VC5410对片上RAM按16bit访问,需将线性码左端补上3bit 0送给接收寄存器DRR1。转换完成后的线性码,传送给DMA控制器,接收DMA控制器立即将此16bit数 据按照其对应的地址写入接收缓冲区DRR BUF中。
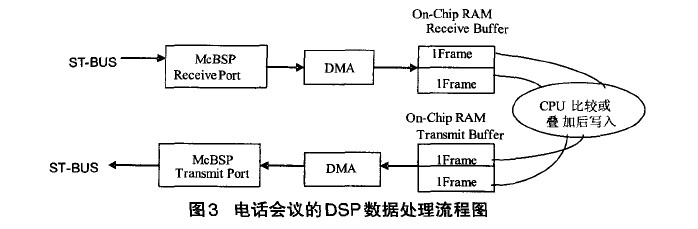
DMA接收完第N帧话音数据后向CPU发送中断。DSP读取命令信箱,在第N+I帧的期间,CPU依据电话会议中与会用户所对应的时隙号,将会议中所包含的语音数据提取出来。根据控制字K,对所有成员的话音进行叠加或比大(得到最大及次大)处理。处理后的数据写入第N+2帧与会用户对应的发送数据缓冲区的地址内。语音数据的发送采用与接收相同的方法。图3为电话会议的DSP数据处理流程图。
3、电话会议系统的算法研究
本文实现的电话会议系统可以在两种模式之间自由选择,下面分两部分介绍本系统的语音处理算法。
混音算法的研究与实现
混音算法常用箝位算法、平均值算法以及自适应加权算法来控制溢出。三种方法各有优缺点,自适应加权算法是目前应用最多的算法,由于引入了可以动态变化的衰减因子这必然会导致算法的运算次数大大增加。
本文提出了一种改进的更适合本系统的混音算法,通过前面的分析我们知道,当与会用户人数较多时,如果选用混音算法会导致话音难以分辨,因此我们只需考虑将最多6路话音进行混音,若超出6路则选用比较法输出。
混音算法过程如下:
首先,对混音数据进行贡献加权处理。即通过将语音流的实际音量和系统当前的混音音量的比值来进行贡献加权处理。贡献加权 处理理论上保证了混音过程声源对整个声音的贡献保持恒定,但对溢出没有进行很好的控制;其次,确定衰减因子f,为简化计算,将衰减 因子的取值分配到一个数组里面;接下来,判断混音后的值在什么范围,即可查表得到相应的衰减因子;最后,让f逐渐恢复到1 。
具体流程如下:
1)初始化f=l。
2)对一帧中的样本按顺序处理:
①线性叠加:
![]()
②贡献加权处理:
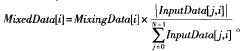
③OutputData[i]=MixedData[t]xf
④若OutputData[i]>Max,则计算 =(MixedData[i]/Max)×10的值, 并判断是否为整数,若是,则让f =[ab一1];若不是,则先对j取整,再让 f1=a[j]。最后令f=f1,OutputData[i]=Max
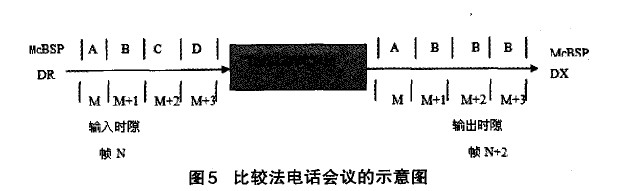
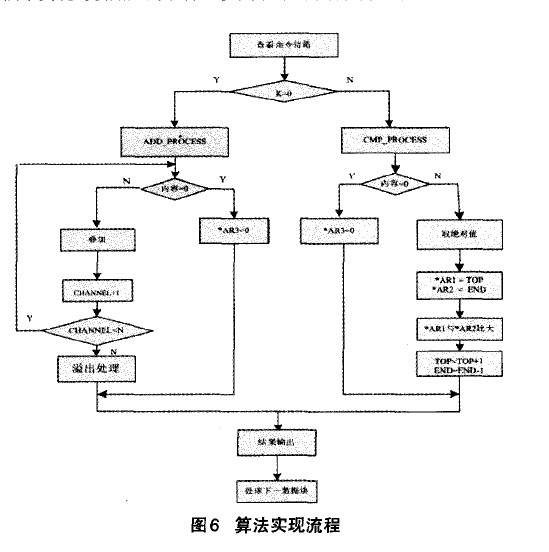
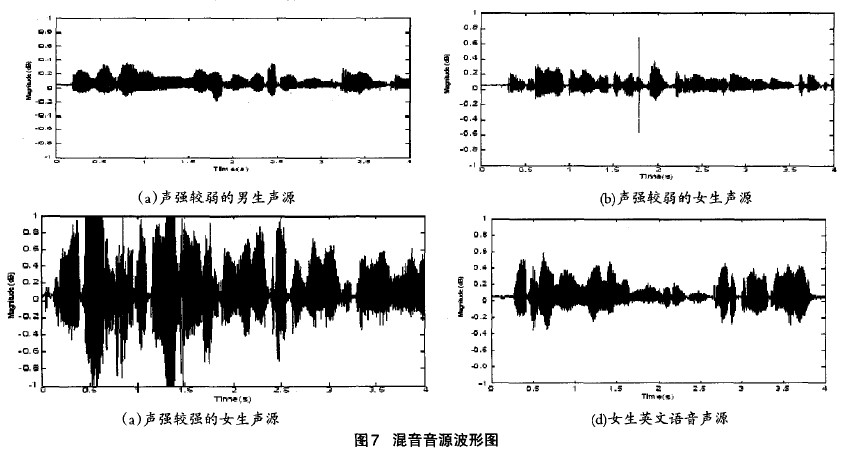
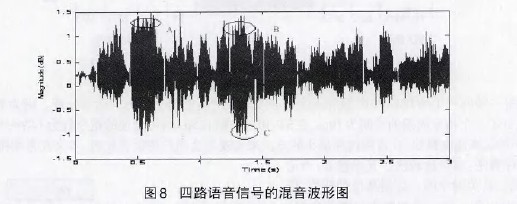
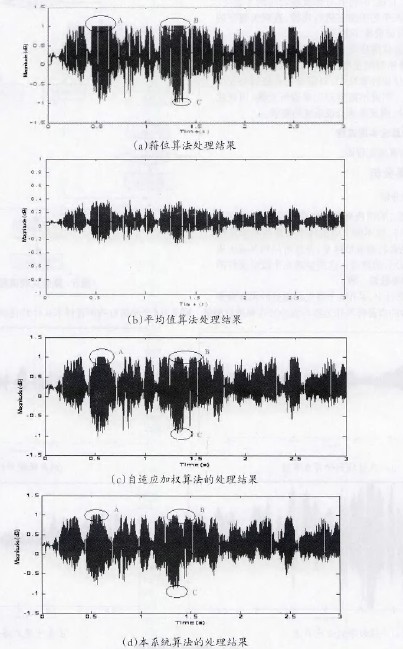
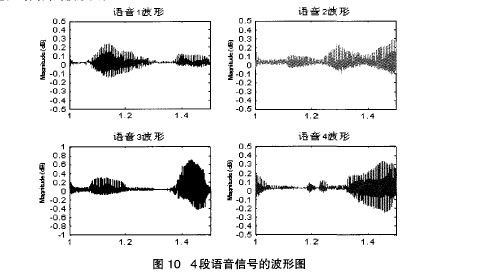
⑤若OutputData[i] 3)如果f<1,f=f+步步长;如果f>l,则令f=l。 这里的步长选择可以依据系统的要求慢慢调整到合适的取值。具体流程图如图4所示。 3.2 比较算法的研究与实现 由前面的分析可知,当与会人数较多时,例如有32个用户同时参与电话会议,同一时刻说话的人数较多时,混音法会造成话音混乱,谁的声音都听不清,此时比较法就会发挥它的优势。 所谓的比较算法就是指对输入的语音信号进行幅值比较,找出话音最大的与会用户B及话音次大的与会用户A。图5是比较算法的电话会议示意图 。以与会用户为4的会议为例,假设在某一时刻A、B、C、D 4 方的第Ⅳ帧PCM编码送人TMS320VC5410,DSP根据主机的要求在第N+1帧期间对4路话音幅度进行比较,假定判断出B的话音幅度最大,A 的话音幅度第二大,于是在第N+2帧期间,将A的话音送给用户B,B的话音送给A、C、D三方用户,B用户听到的是A用户的声音,其他用户听到的是B用户的声音。 电话会议要求在每一帧所产生的DMA中断服务程序中必须完成对所有与会用户的话音处理。因为TMS320VC5410的运算速度为100MIPS,因此该DsP一个指令周期的时间为10ns,在ST—Bus一帧125txs内可处理的指令数为125p~s/10ns=12500条。 因此,需要找到一种运算速度最快,且占用内存最小的方法来实现与会用户的话音比较,本文在常用排序算法的研究的基础上 提出了一种改进的排序算法:逐位比较法。其思想为:当记录的关键字是正整数时,从关键字的二进制高位到低位,依次取出每个关键字相对应的一位二进制数进行两两比较,然后根据比较位是 ‘1’或‘0’将其分别放在对应的子表中,按同样的方法对子表中的关键字进行比较,直到关键字的最低二进制位将所有记录排序完毕。 逐位比较法是由位排序演变过来的,由于位运算和位比较的速度较快,排序时间主要花费在记录的交换上。而在本系统采用的逐位比较算法中,只需要找到幅值最大的数据及次大的数据。因此不需要对记录进行交换,因此按位比较法的速度很快,满足电话会议系统的要求。 3.3 电话会议系统的算法实现流程 图6为本系统的算法流程图。 4、算法仿真及结果分析 4.1混音算法及结果分析 在仿真测试平台,利用现有的一些声音样本,用Matlab工具转化成波形文件,把不同文件的样本按照各种算法进行叠加,即可得到混合后的波形样本,并且可以用Matlab里的相关函数播放混合后的声音。这里要求几个波形文件的采样率、样本位数等参数要一致。 在Matlab测试试平台上,采用4个事先录制好的采样频率为8KHz、时长为4秒的声音样本作为参与混合的音频进行测试。图7为4个录制好的声音样本文件转化成波形文件后的图形。 图8为4路语音信号的混音波形图,从图中可以看出,由于混音音源中有两路女生的话音幅度较大,因此混音后输出的话音幅度发生了较为严重的溢出,如A、B、C三处所示。混音效果很不好,噪音很大,基本上很难听清楚话音内容。 图9为用不同方式对4路语音信号进行混音处理后的话音波形图: 由图9(a)可以看出,箝位算法在最大和最小临界值处生硬的切了一刀,混音后的声音引入了较大的噪音。图9(b)为用平均值处理后的结果。该算法解决了混音后卢音幅度的溢出问题,但波形的幅度偏小,和混音前一路的波形幅度差不多,混音后的声音较小。图9(c)、(d)是自适应加权算法及本系统算法的处理结果。由图可见A、B、c三处都对溢出的语音信号进行了平滑处理,与自适应加权算法相比,本系统的算法语音溢出点数减少,另外,对溢出处的处理比较平滑,没有跳跃现象出现,整体质量有很大提高。 4.2比较算法及结果分析 为了观察到较好的实验效果,这里只对4段语音信号进行分析,仿真结果同样能够说明多路语音信号的处理结果。图l0为4段语音信号用Matlab 工具转化成波形文件后的波形图。下图可以很好的表示出话音音量的大小。为了更好的说明仿真结果,这里我们只选取1至1.5秒这段时间内的波形图 由图10所示,4段声音文件在不同时间段内声音的大小不同,DSP每隔125s对4段语音信号的量化编码值进行一次比较。虽 然每帧DsP都要对4段语音信号进行比较,但是由于声音的恒定性,在几帧甚至几十帧内,输出的比较结果都是一致的,这样才能清楚地听清楚每个人的讲话。在这里为了对算法进行说明,只采用了短短0.5秒的时间内的声音数据进行比较。 用逐位比较法对4段0.5秒的语音信号进行比较,得到每帧的最大话音及次大话音。图11为0.5秒内的比较结果。 5、结论 本文所提出的电话会议系统方案能很好地解决实际应用中的实时性、高效性,系统简单易行且能保证合成分量音频特性的要求。克服了现有电话会议系统存在的缺点和不足,此方案适合中小企业使用的电话会议系统方案。 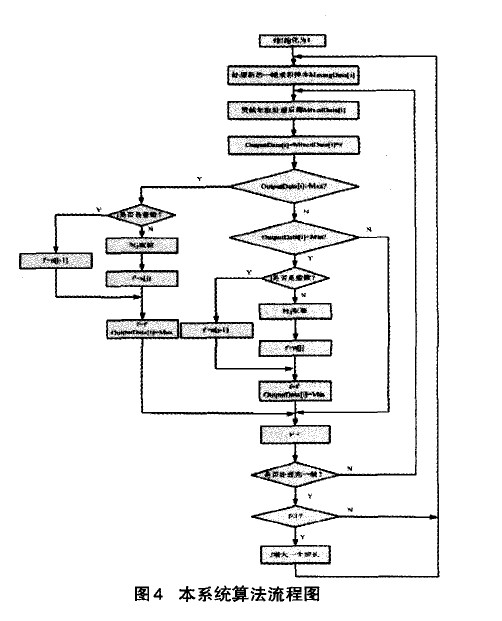
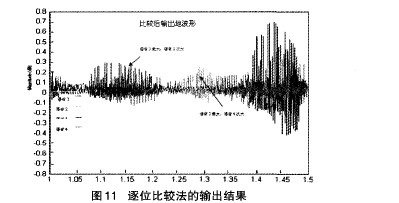
由图11可见,在1到1.O3秒期间,语音4要高于其他3路话音,语音3为次大话音。在这段时间内,DSP将用户3的话音存入用户4所对应的时隙,而将用户4的话音输出给其他3个用户所对应的时隙。而在1.38到1.48这段时间内,语音3的话音幅度一直最大,语音4为次大话音,因此,用户3听到的是用户4的话音,而其他3个与会用户听到的是用户3的声音。
40088 411661033743080@qq.com
中国广东省深圳市南山区西丽九祥岭工业区10栋3楼